Professional Development @ Boulder
Learning Multi-Agentic AI Systems

This Spring, I’ve reached the midpoint of my program in computer science at the University of Colorado Boulder (UCB) and am starting to branch out to more interesting courses outside the core curriculum. One of these is CSPB 3112 Professional Development in Computer Science where I can choose any CS topic and work on it during the semester for one credit.
Therefore, I’m going all in on agentic AI systems. Here’s what I’m proposing to work on during the next 13 weeks.
Project Proposal
This project is about learning how to design, build and deploy multi-agentic AI systems.
Vision statement
This project will add to my skills in AI system design and development following the different projects implemented during the CSPB program:
CSPB 1300: C++ Implementation of a Basic Recurrent Neural Network.
CSPB 4830: n8n AI automation workflow for construction costing.
CSPB 3308: AI Technical Interview Assistant.
Personal Project: AI Grader & Rich Feedback for continuous education programs.
Motivation
My moonshot goal is to obtain a PhD in Computer Science and I’m studying different CS topics such as HCI, AI and Social Computing and their application in adult learning (Andragogy), upskilling, reskilling, self fulfillment and career change.
Specific and measurable goals (learning objectives) for the project Ability to understand, explain and implement the following:
Agent Design Concepts (Chain of Thought - CoT and Reasoning/Acting Framework - ReAct)
Multi Agent Design Patterns (Router, Parallel, Serial, Orchestrator)
Adding Guardrails to Agent output (Programmatic and LLM Judging)
Use of Short and Long Term Memory
Retrieval Augmented Generation (RAG) and vector databases (Pinecone, PgVector, etc…)
Integration with Tools (Model Context Protocol)
Risks to project completion, possibly including:
Busy with life and work commitments.
Mitigation strategy for the risks listed above
Take a structured approach to learning by following the Udacity Agentic AI Curriculum.
Implement the 4 projects in the Udacity Agentic AI course and have them graded.
Review the Github Actions course on MS certification page and Linkedin Learning.
Blog about my learnings on a weekly basis.
Choose a capstone project with publicly available data.
Follow this loosely designed schedule:
[x] Week 01: Prepare project proposal & research topics
[x] Week 02: Udacity: Course 1 - Prompting For Effective Reasoning & Planning - Submit P1
[x] Week 03: Udacity: Course 2 - Agentic Workflows - Submit P2
[x] Week 04: Udacity: Course 3 - Building Agents
[x] Week 05: Udacity: Course 3 - Building Agents
[x] Week 06: Udacity: Course 3 - Submit P3
[x] Week 07: Udacity Course 4 - Multi-Agent Systems
[x] Week 08: Udacity Course 4 - Multi-Agent Systems
[x] Week 09: Udacity Course 4 - Submit P4 & Obtain Certificate
[x] Week 10: Github Actions - Review MS official course
[x] Week 11: Github Actions - Review Linkedin Learning Course - Take Exam
[x] Week 12: Capstone Project: Graduate Record Exam (GRE) AI Essay Tutor
[x] Week 13: Final Project Report
Project assessments - provide a list of evaluation criteria for the project
Obtained the Udacity Agentic AI Nanodegree. [x]
Deployed an Agent using a CI/CD pipeline. [x]
Bonus: Take the Github Actions Certifications Exam [x]
Project portfolio link: https://starterpad.com
Week 12 [Apr 13 - Apr 20, 2026]
What did you do last week?
Last week was all about deploying and evaluating results for the multi-agentic GRE essay grader. I used Render for quick deployment from my Github repo where I created a Postgres Db instance and two web service instances to deploy the Python/FastAPI backend and Next.JS for the frontend.
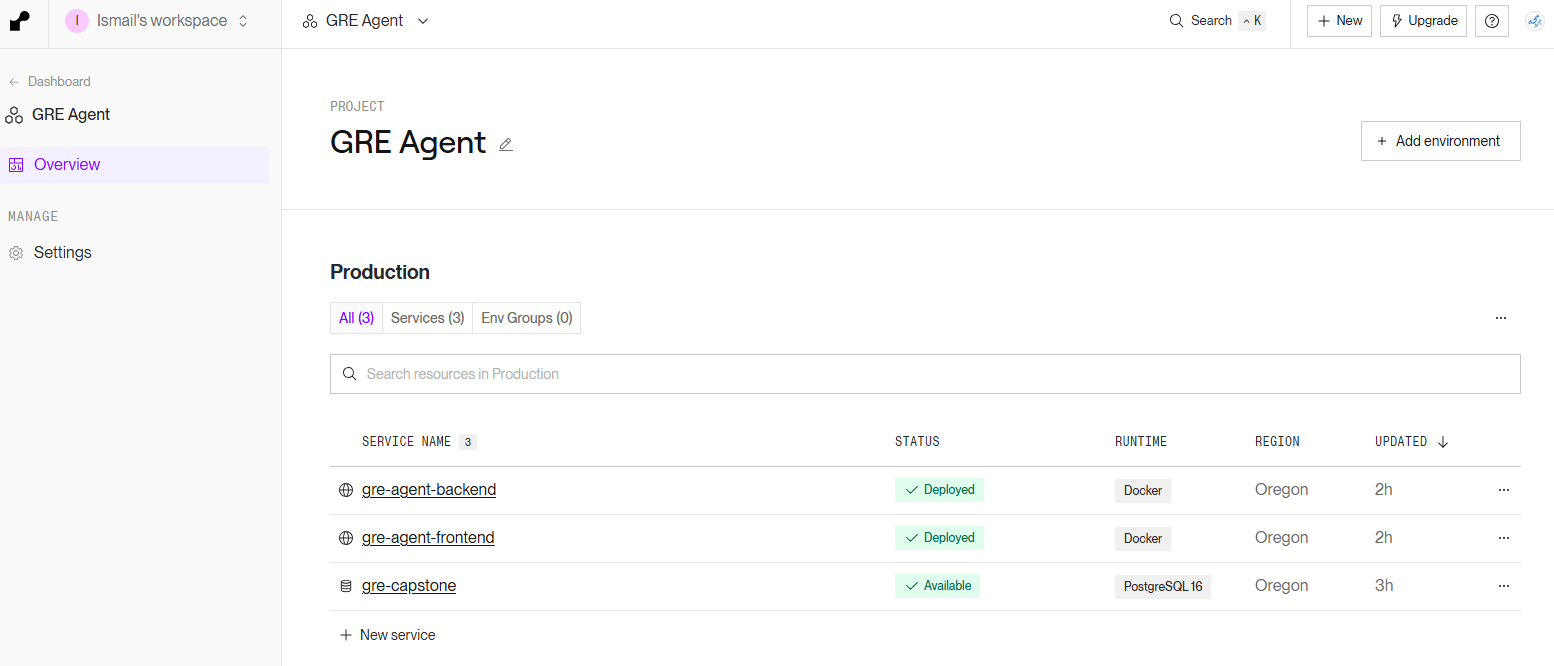
The Web App can be accessed from here. Since I’m on the Render free plan, it might take a couple of minutes to run.
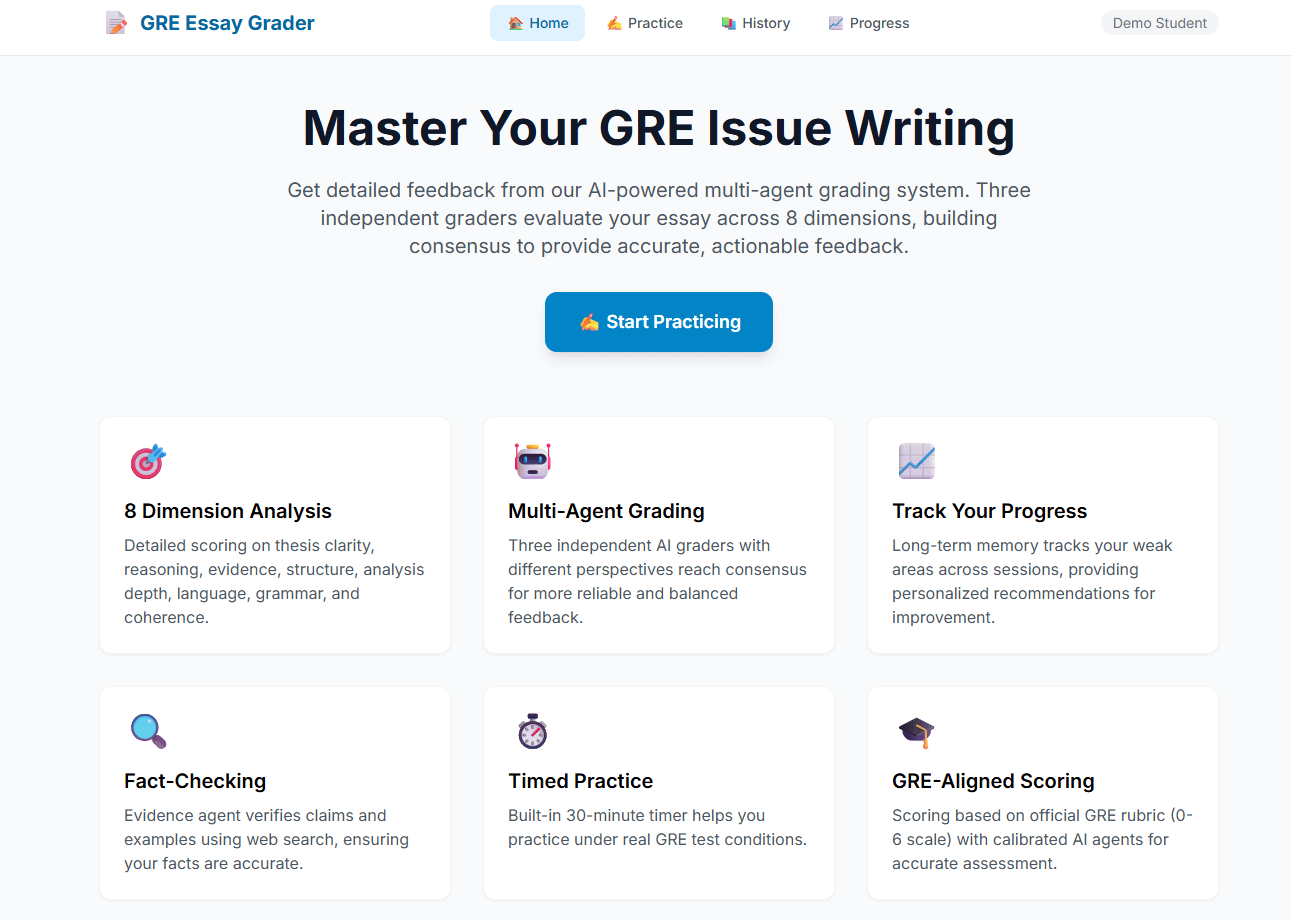
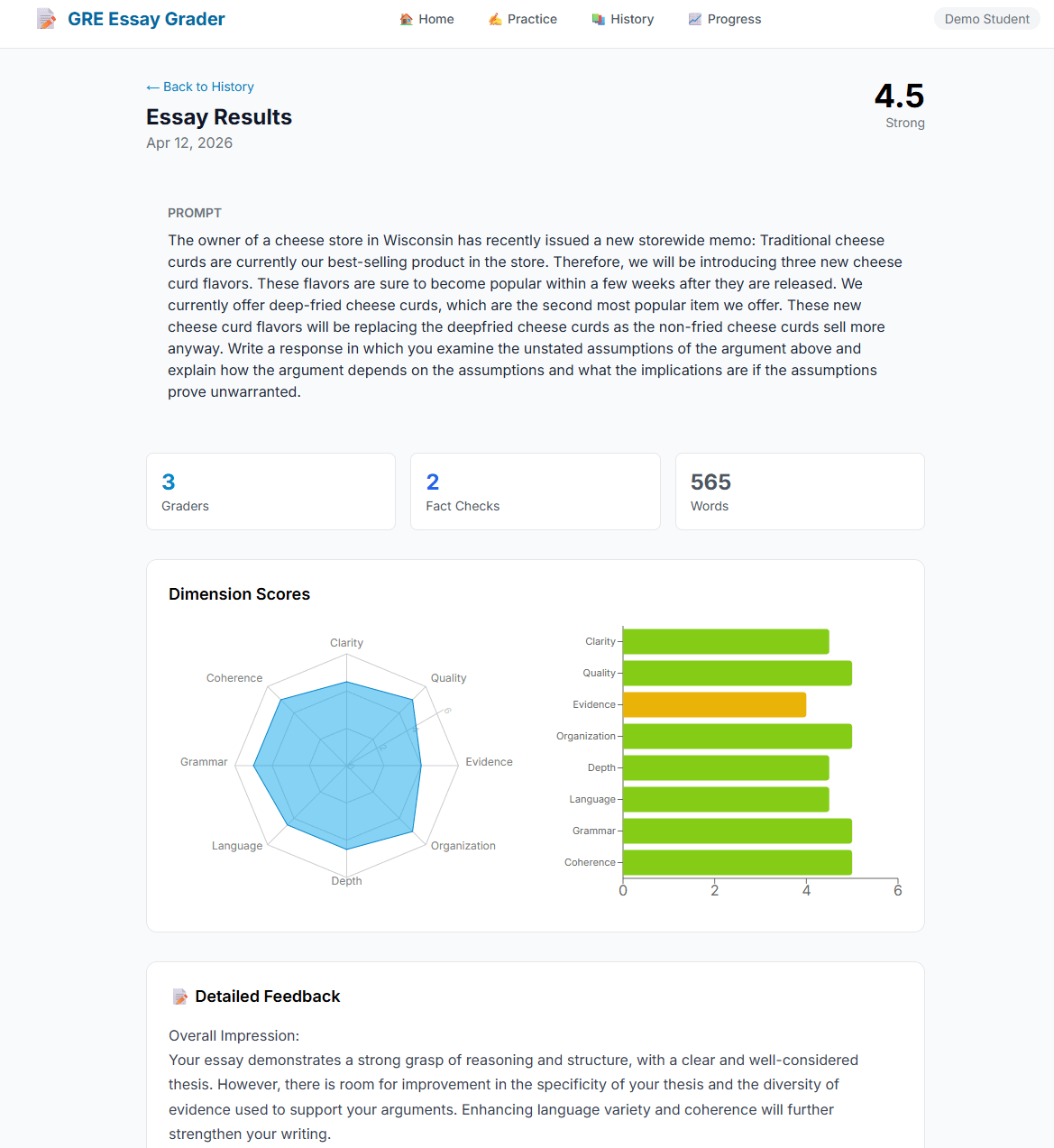
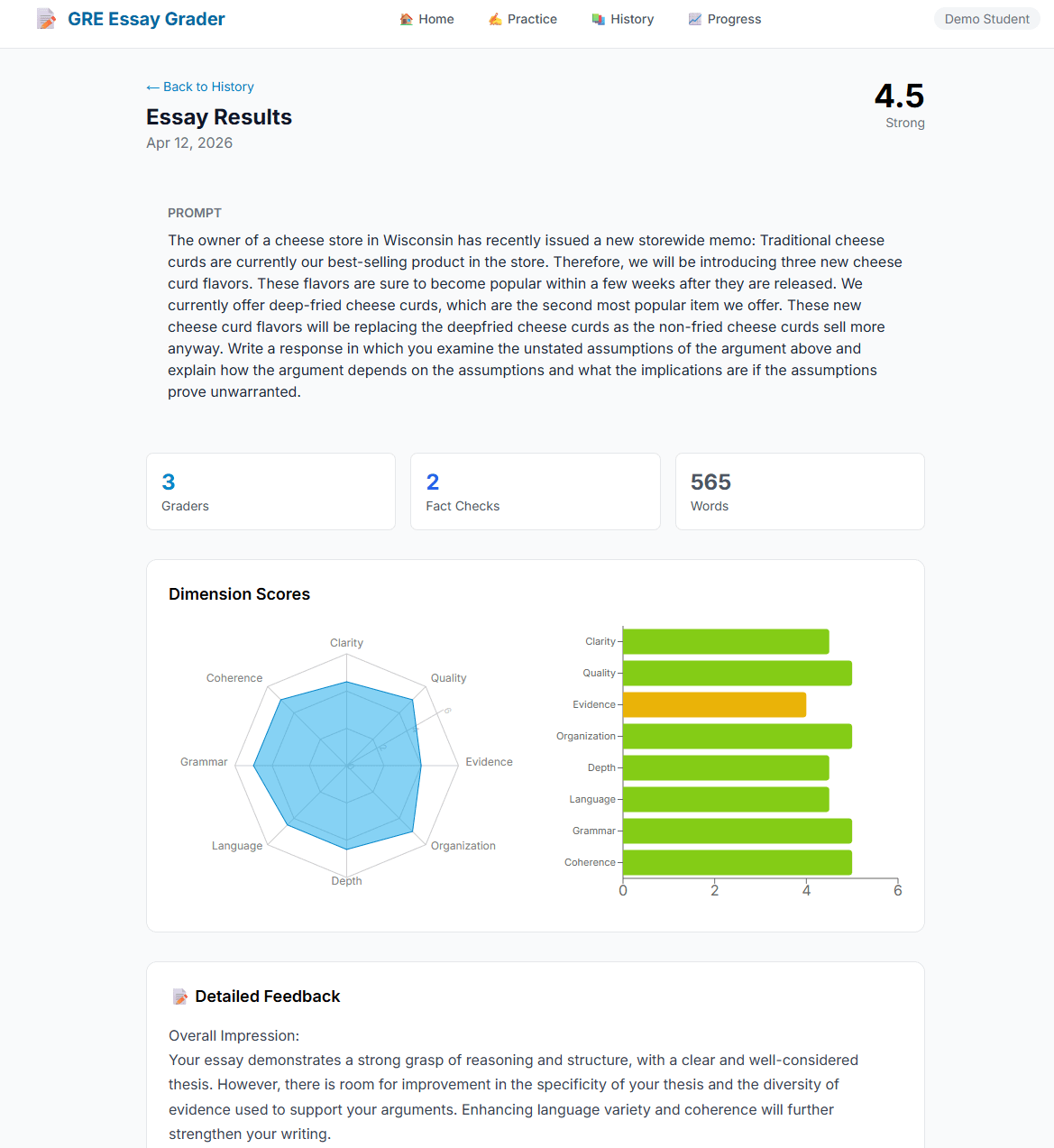
I also worked on evaluating the performance of the Multi-agent system and used two essay prompts with six responses each labeled with an official score from the Educational Testing Service (ETS) from 6.0 down to 1.0.
Each run of the GRE grader takes 1 to 2 minutes to complete and costs about 20 cents.
Prompt #1:
As people rely more and more on technology to solve problems, the ability of humans to think for themselves will surely deteriorate.
Discuss the extent to which you agree or disagree with the statement and explain your reasoning for the position you take. In developing and supporting your position, you should consider ways in which the statement might or might not hold true and explain how these considerations shape your position.
Results: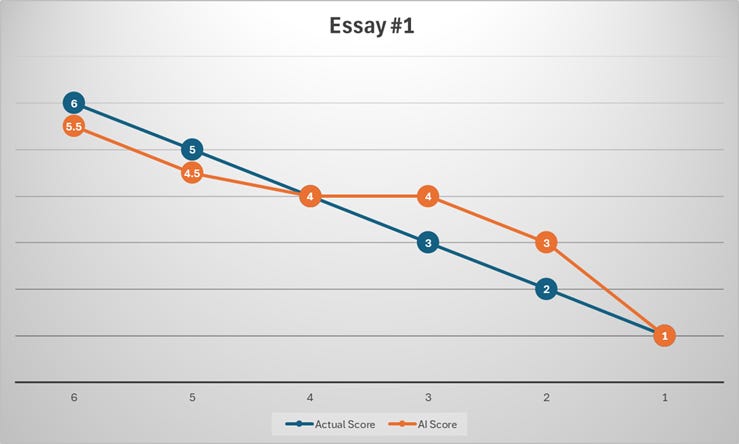
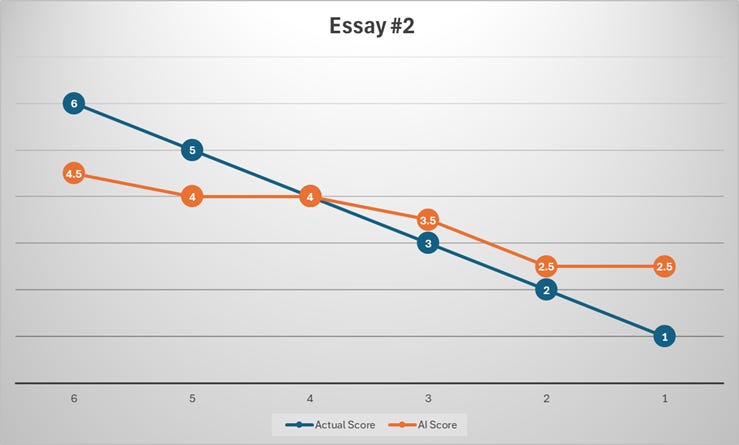
Prompt #2:
The best ideas arise from a passionate interest in commonplace things.
Write a response in which you discuss the extent to which you agree or disagree with the statement and explain your reasoning for the position you take. In developing and supporting your position, you should consider ways in which the statement might or might not hold true and explain how these considerations shape your position.
Results: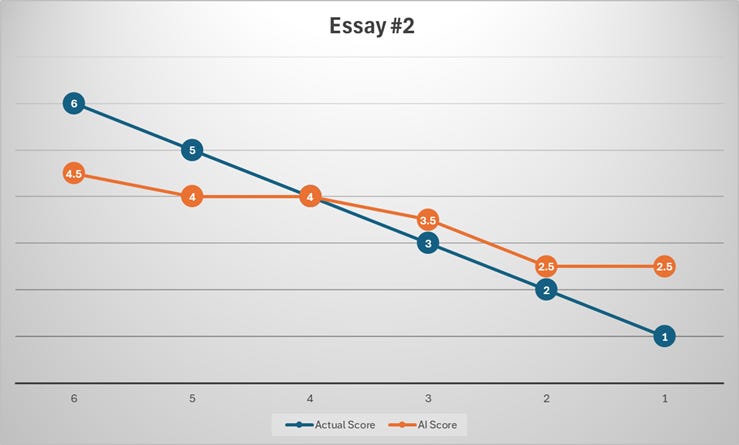
Observations:
Overall scoring comparison
The AI is close on average but not consistently accurate essay by essay. The official average is 3.5, while the AI average is about 3.58.
The bigger issue is calibration, not the mean: the AI is exact on only 3 of 12 essays, and its average absolute error is about 0.67 points.
The AI shows clear regression to the middle: it tends to score strong essays too low and weak essays too high. This pattern is visible across the full set of rows and variances.
Where the AI matches reasonably well
IDs 3, 6, and 9 are essentially aligned: the AI gave the same score as the official score.
IDs 1, 2, 10, and 11 are only off by 0.5, which is fairly acceptable for GRE-style scoring.
Where the AI misses most
ID 7: official 6, AI 4.5 → biggest underscore of a strong essay (+1.5 variance).
ID 12: official 1, AI 2.5 → biggest overscore of a very weak essay (-1.5 variance).
IDs 4 and 5: official 3 and 2, AI gives 4 and 3 → both are meaningfully too generous.
ID 8: official 5, AI 4 → another noticeable underscore of a stronger essay.
Pattern in score behavior
For the top-band essays (scores 5–6), the AI almost always scores them lower than the official benchmark.
For the low-band essays (scores 1–3), the AI often scores them higher than the benchmark.
For the middle-band essays (score 4), the AI is much better calibrated.
Next Steps:
Although we are at the end of the course but more evaluation is required to calibrate the agentic system and compare to a much simpler approach (direct LLM scoring). I believe three areas will provide good improvement:
Model: The model used is GPT-4o, upgrading the model to GPT 5 should result in improved performance.
Prompt: I did not do any significant prompt engineering and so revising and tweaking the system prompts should be useful.
Zero-Shot: The agents were deployed with only the grading rubric provided in the system prompts and no graded examples. I believe that a Few-Shot approach could significantly improve the outcome.
What do you plan to do this week?
Just finalize and submit the final report and add my final post.Are there any impediments in your way?
None.Reflection on the process you used last week, how can you make the process work better?
Excellent outcome from the course. All my objectives are met including the bonus objectives. I’m confident in building multi-agentic systems now and will continue learning about using LangChain, LangGraph and LangSmith. My Replit App FounderTable is also a finalist in the top 100 apps from over 6,000 submissions.
Week 11 [Apr 6 - Apr 13, 2026]
What did you do last week?
I worked on the capstone project which is a multi-agent GRE exam Issue essay grader. The Graduate Record Examination (GRE) is a standardized test used for admission to graduate programs (Master’s, MBA, some PhDs). The analytical part consists of writing about an issue within 30 minutes. The essay is scored from 6.0 in half point increments.
The first step I worked on was to study the problem and collect data for scored essays from the internet. I was able to put together a labeled dataset of over 47 essays, each with both a prompt, a student response, a score and feedback. This gave me a solid foundation to understand what makes a 6.0 essay different from a 1.0 and it’s not just good grammar.
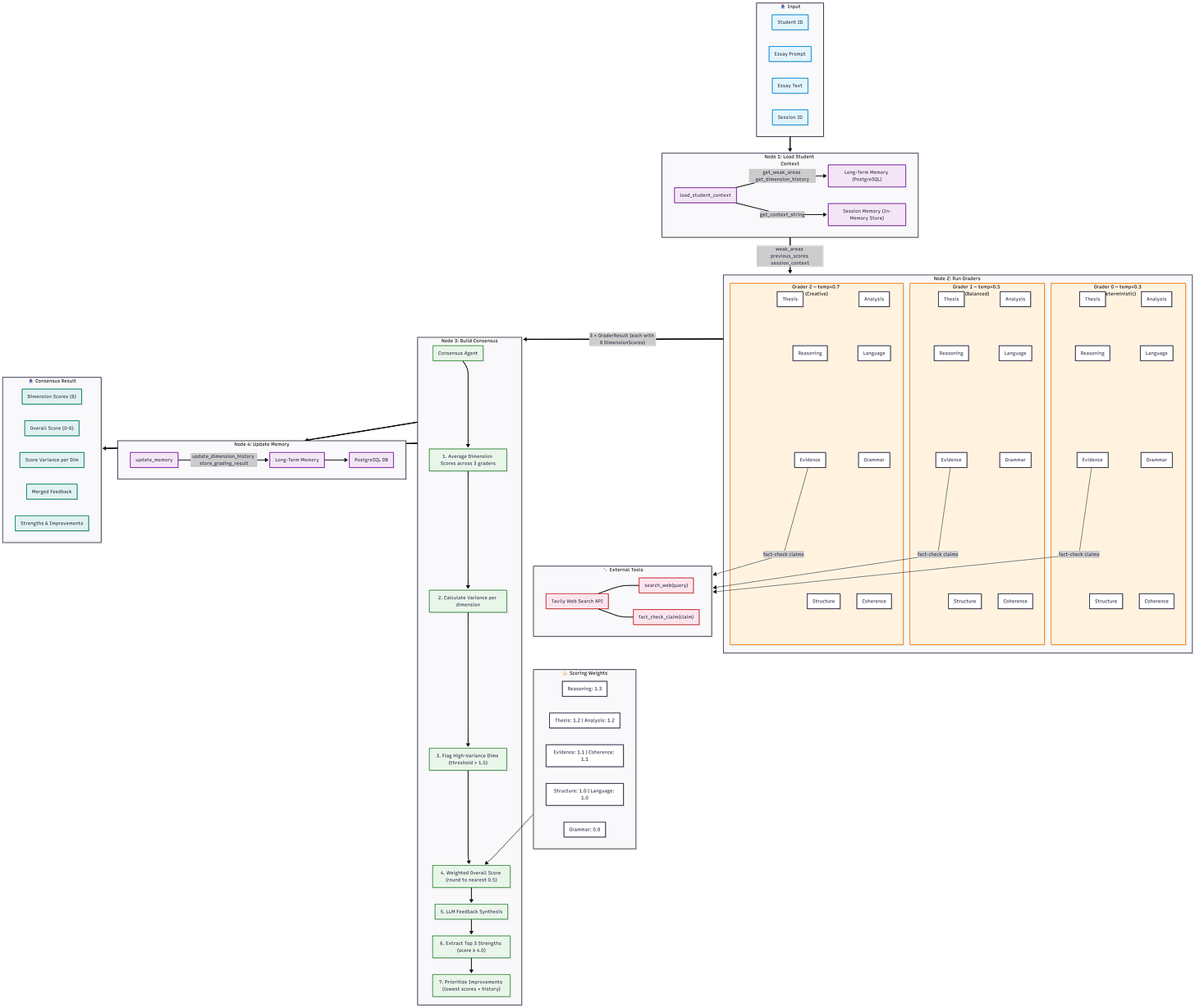
The Architecture: Why One Grader Isn’t Enough
The ETS (Educational Testing Institute) grades the GRE essay by an Automated AI program (e-rater) and at least one human reader. The final score is averaged and rounded to the nearest half-point. If the human and AI scores differ significantly (usually more than one point), a second human reader is brought in to review.
Therefore, I designed a system with 3 independent graders running in parallel, each operating at a different LLM temperature (0.3, 0.5, and 0.7). One is strict and consistent, one is balanced, and one is a bit more creative in its evaluation. It’s like having three professors with different personalities read the same essay.Each grader doesn’t just slap a number on the essay and call it a day. It deploys 8 specialized agents that each evaluate a different dimension of writing:
Thesis: Is there a clear position?
Reasoning: Does the argument actually make sense?
Evidence: Are the examples real? (More on this in a sec.)
Structure: Is the essay well-organized?
Analysis: How deep does the thinking go?
Language: Is the vocabulary precise and varied?
Grammar: Spelling, punctuation, mechanics.
Coherence: Does it all come together persuasively?
That’s 24 agent evaluations per essay (8 agents × 3 graders), all running concurrently.
The Fun Part: Fact-Checking Students in Real Time
The Evidence agent has access to web search tools via the Tavily API. If a student writes “studies show that 90% of people prefer remote work,” the agent can actually go verify that claim. It’s like having a grader who Googles your citations mid-read.
Building Consensus
Once all three graders finish, a Consensus Agent steps in to reconcile their scores. It averages the dimension scores, calculates variance (to spot where the graders disagreed), and uses a weighted formula to compute the final score. Reasoning is weighted the heaviest at 1.3, while Grammar is the lightest at 0.8, which mirrors how real GRE graders prioritize critical thinking over comma placement. An LLM then synthesizes all the feedback into one coherent, constructive response for the student.
Memory That Actually Remembers
The system tracks each student over time using a long-term memory layer backed by PostgreSQL. It knows your weak areas, sees if you’re improving or declining, and tailors its feedback accordingly. So if you keep writing essays with weak thesis statements, it won’t just tell you, it’ll keep telling you, with specific suggestions, until you get it right.
The Tech Stack
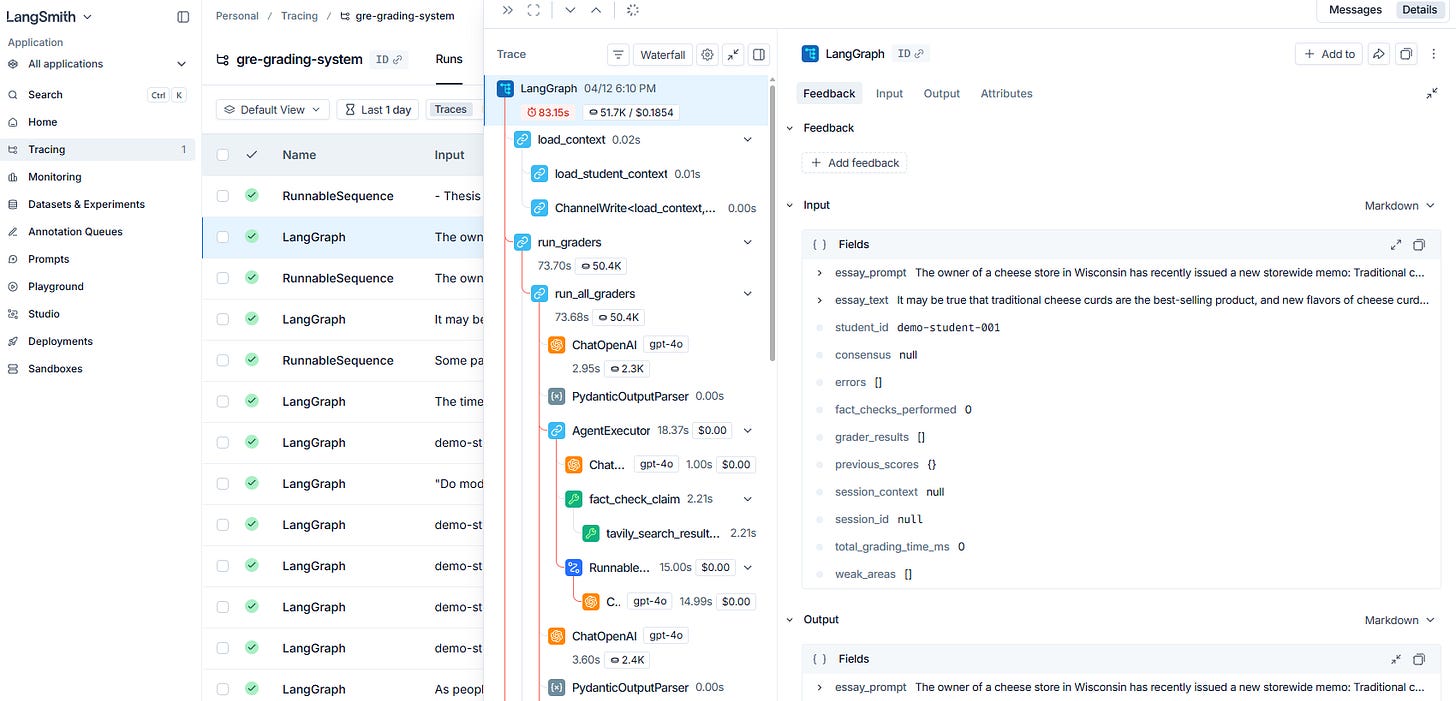
The whole pipeline is orchestrated with LangGraph as a 4-node state graph.
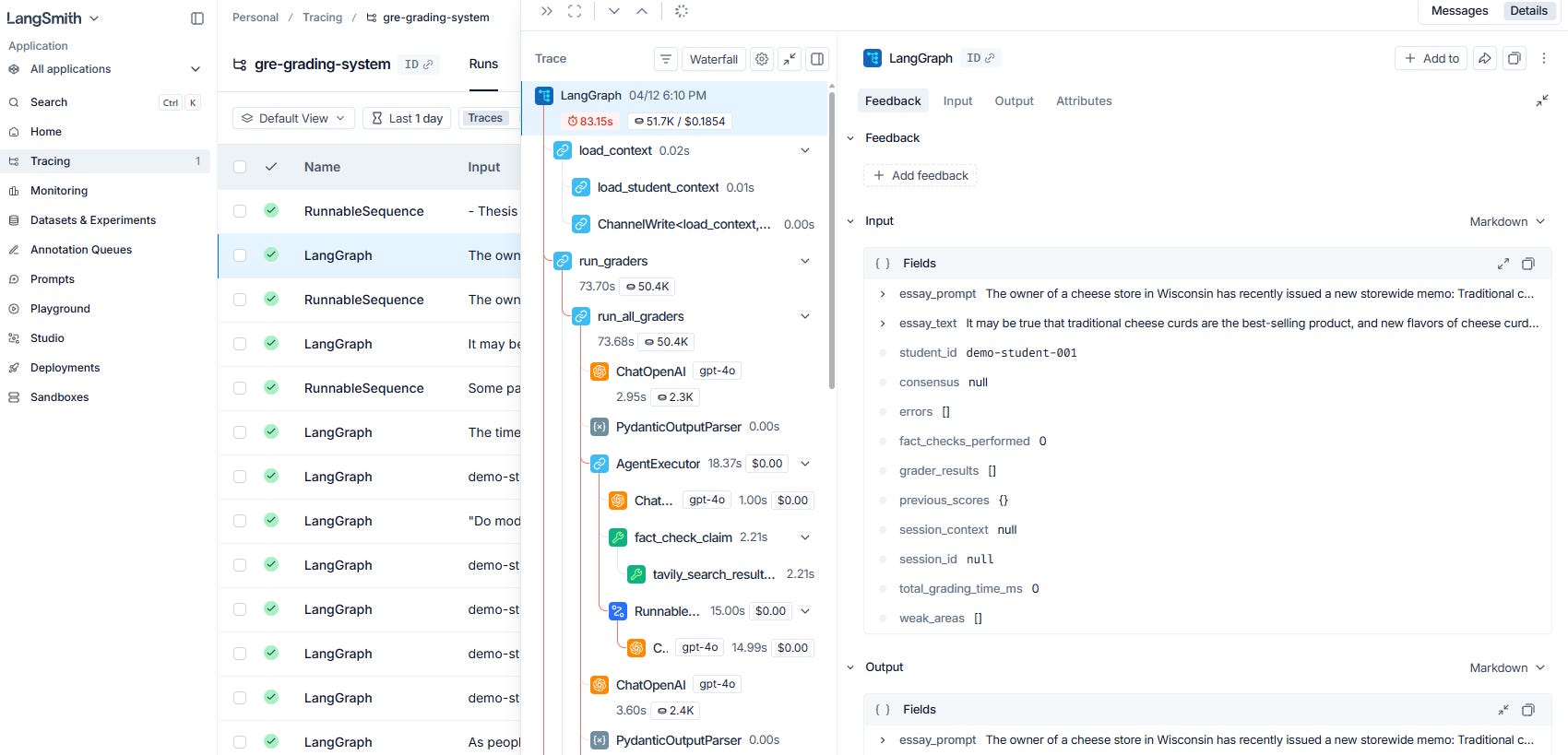
(load context → run graders → build consensus → update memory)The backend runs on FastAPI, the frontend is Next.js with Tailwind CSS, and everything is containerized with Docker Compose. PostgreSQL handles persistence, and the grading agents are powered by LangChain with OpenAI GPT-4o as the underlying LLM.
I also used LangSmith for observability (meaning that tracing the behavior of the multi-agent system). LangSmith show the exact trace and how much time as well as how many tokens were used by each agent.
What do you plan to do this week?
This week, I’ll work on multi-agent system deployment and start writing up the final report.Are there any impediments in your way?
I have my second oral exam on Wednesday, hopefully should be much better prepared this time.Reflection on the process you used last week, how can you make the process work better?
Really got a rush from building this to fully functional full-stack application in a couple of hours (~ 6 hours). I used Github Copilot with Claude Opus 4.5 to assist with the code after I figured out the specifications and provided the architecture.
Week 10 [Mar 30 - Apr 6, 2026]
Here are the updates so far:
What did you do last week?
Since I completed my learning objectives already, last week was a bit chill with more focus on reading and learning more about LangChain, LangGraph and LangSmith. I watched a couple of Youtube videos and started reading Learning LangChain. I bought an online PDF/ePub version from Humble Bundle which was really cool. They had a collection of 12 O’Reilly Machine Learning Books for $25 with the revenues going to charity (just over $27,000).
In addition, I was playing around with building my Replit App. I pivoted my idea and renamed the startup to FounderTable where the would be founders can pitch and debate their ideas to a panel of world famous founders, developers and designers and get their feedback (using RAG and and LLM on the backend).
With that change, I really saw a huge bump in views, votes and “imaginary currency” earnings as well as feedback from the community.

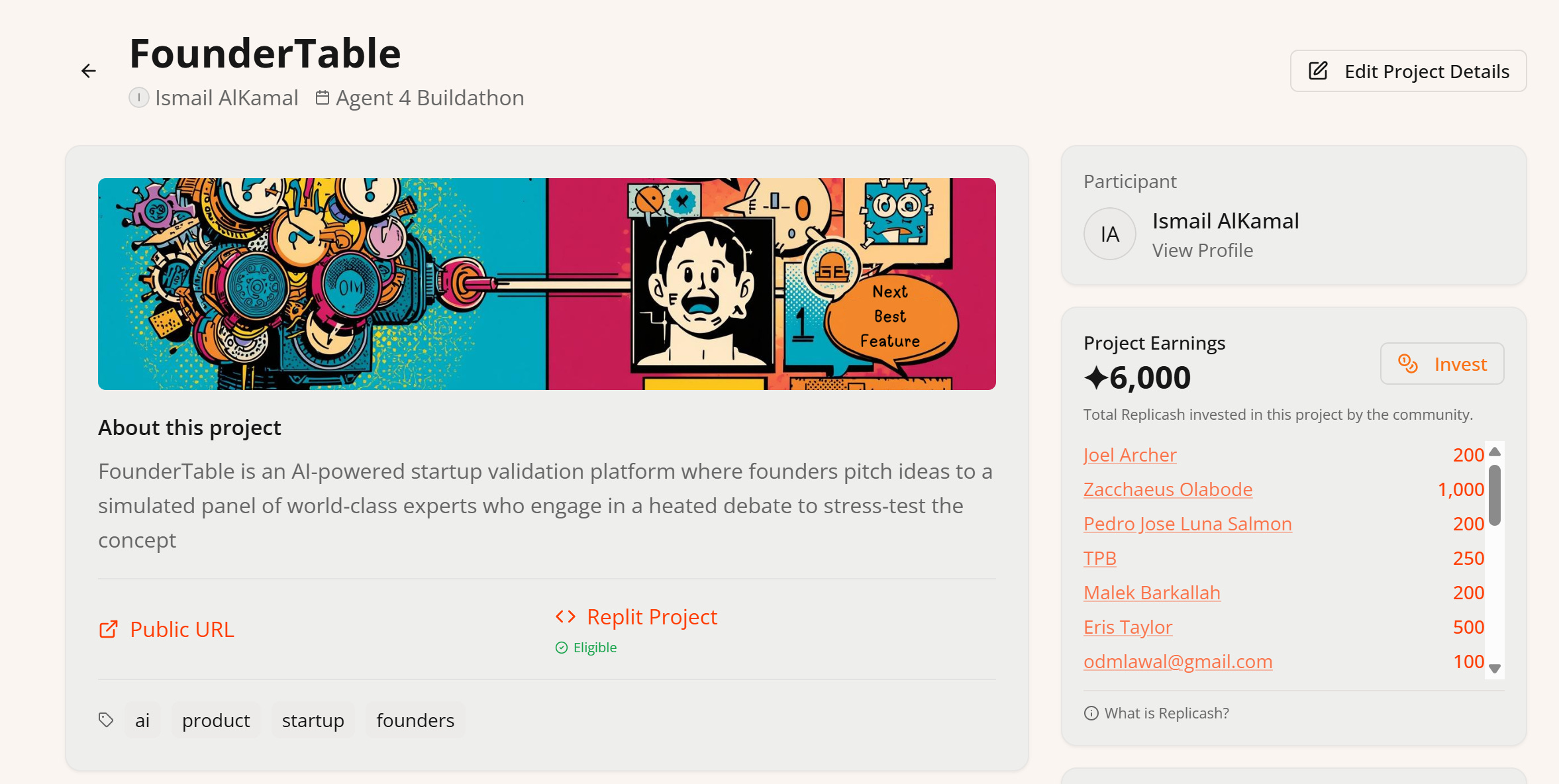
Here is some feedback from users after the pivot:



If you’d like to support the project, you can check it at the buildathon site.
What do you plan to do this week?
This week, I’ll take things seriously to kickstart the capstone project.Are there any impediments in your way?
It is becoming difficult to focus during the final stretch especially while studying for my second oral exam and submitting the final project for the Intensive Programming Workshop (CSPB 3010) during the next two weeks. I don’t really do well on live technical interview calls under pressure and kind of botched my first one because of very silly mistakes so need to focus on my second to be able to pass the course with an A.Reflection on the process you used last week, how can you make the process work better?
Just need to get my game face on and plow through the remaining weeks.
Week 09 [Mar 23 - Mar 30, 2026]
What did you do last week?
Last week, I worked on two main tasks that include:
Deploy the Udacity project #4 multi-agent system onto AWS.
Participate in the Replit4 Buildation using their latest Agent 4 tool.
Deployment was a great exercise and I used Github Copilot to assist with the deployment process after thinking about and setting up the following deployment plan:
Open up an endpoint for my agentic system to receive customer requests. That can be done by using FastAPI.
Dockerize the application and push the image to ECR (Amazon Elastic Container Registry)
Create a running container from the stored image in ECS (Amazon Elastic Container Service)
Build a Github Actions workflow to allow automated CI/CD
FAST API
The multi-agent system provides the ability to quote for paper supplies and to automatically process orders through the orchestrator agent.
Two main endpoints were created at /quote and /process-order to either get a quote or process a new order in addition to /health and /ready to check if the multi-agent system is ready.
This is an example request:
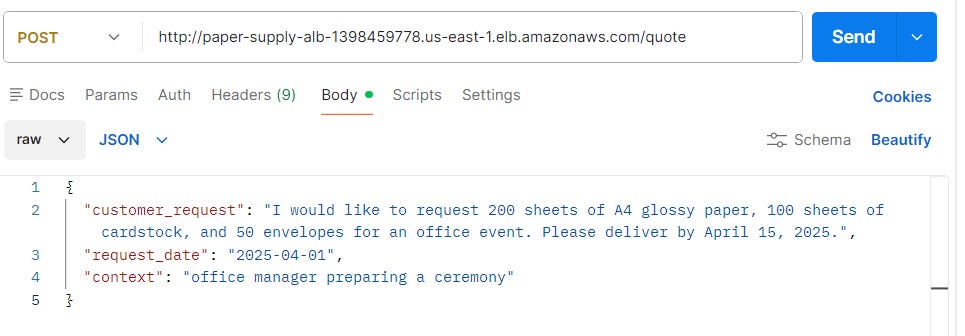
and relevant response to get a quote":
{
"status": "success",
"parsed_items": [
{
"requested_name": "A4 glossy paper",
"canonical_name": "Glossy paper",
"quantity": 200
},
{
"requested_name": "cardstock",
"canonical_name": "Cardstock",
"quantity": 100
},
{
"requested_name": "envelopes",
"canonical_name": "Envelopes",
"quantity": 50
}
],
"inventory_assessment": {
"supported_items": [
{
"requested_name": "A4 glossy paper",
"canonical_name": "Glossy paper",
"quantity": 200,
"unit_label": "units"
},
{
"requested_name": "cardstock",
"canonical_name": "Cardstock",
"quantity": 100,
"unit_label": "units"
},
{
"requested_name": "envelopes",
"canonical_name": "Envelopes",
"quantity": 50,
"unit_label": "units"
}
],
"unsupported_items": [],
"in_stock_items": [
{
"item_name": "Cardstock",
"quantity": 100,
"stock_available": 395,
"unit_price": 0.15
}
],
"reorder_items": [
{
"item_name": "Glossy paper",
"requested_qty": 200,
"stock_available": 187,
"shortage": 13,
"eta": "2025-04-02",
"unit_price": 0.2,
"reorder_cost": 2.6
},
{
"item_name": "Envelopes",
"requested_qty": 50,
"stock_available": 0,
"shortage": 50,
"eta": "2025-04-02",
"unit_price": 0.05,
"reorder_cost": 2.5
}
],
"blocked_items": [],
"can_fulfill": true,
"reason": []
},
"quote": {
"line_items": [
{
"requested_name": "A4 glossy paper",
"item_name": "Glossy paper",
"quantity": 200,
"unit_price": 0.2,
"line_total": 40.0
},
{
"requested_name": "cardstock",
"item_name": "Cardstock",
"quantity": 100,
"unit_price": 0.15,
"line_total": 15.0
},
{
"requested_name": "envelopes",
"item_name": "Envelopes",
"quantity": 50,
"unit_price": 0.05,
"line_total": 2.5
}
],
"subtotal": 57.5,
"discount": 0.0,
"total": 57.5,
"historical_matches": [
{
"original_request": "I need to order 10 reams of standard copy paper, 5 reams of cardstock, and 3 boxes of assorted colored paper. I need the order delivered by April 10, 2025, for an upcoming meeting.",
"total_amount": 60,
"quote_explanation": "For your order of 10 reams of standard copy paper, 5 reams of cardstock, and 3 boxes of assorted colored paper, I have applied a friendly bulk discount to help you save on this essential supply for your upcoming meeting. The standard pricing totals to $64.00, but with the bulk order discount, I've rounded the total cost to a more budget-friendly $60.00. This way, you receive quality materials without feeling nickel and dimed.",
"job_type": "school board resouorce manager",
"order_size": "large",
"event_type": "meeting",
"order_date": "2025-01-01T00:00:00"
},
{
"original_request": "I would like to place an order for 500 sheets of high-quality cardstock in various colors, 200 sheets of standard printer paper, and 1000 flyers printed in full color. I need these supplies delivered by April 15, 2025, to ensure everything is ready for the festival. Thank you.",
"total_amount": 780,
"quote_explanation": "Thank you for your order! For the 500 sheets of high-quality cardstock in various colors, we will provide a bulk discount, reducing the cost to $0.12 per sheet. The 200 sheets of standard printer paper will remain at $0.05 per sheet. For the 1000 full-color flyers, we'll keep the cost at $0.15 each. With these adjustments, we've rounded the total to ensure you get a great deal while keeping your festival budget in check.",
"job_type": "event manager",
"order_size": "small",
"event_type": "festival",
"order_date": "2025-01-01T00:00:00"
},
{
"original_request": "I would like to request a large order of high-quality paper supplies for an upcoming event. We need 500 reams of A4 paper, 300 reams of letter-sized paper, and 200 reams of cardstock. Please ensure the delivery is made by April 15, 2025. Thank you.",
"total_amount": 96,
"quote_explanation": "Thank you for your large order! We have calculated the costs for 500 reams of A4 paper at $0.05 each, 300 reams of letter-sized paper at $0.06 each, and 200 reams of cardstock at $0.15 each. To reward your bulk order, we are pleased to offer a 10% discount on the total. This brings your total to a rounded and friendly price, making it easier for your budgeting needs.",
"job_type": "event manager",
"order_size": "large",
"event_type": "meeting",
"order_date": "2025-01-01T00:00:00"
}
],
"quote_explanation": "The quote uses current catalog pricing for 3 matched item(s). Similar historical quotes were reviewed for consistency."
},
"timestamp": "2026-04-01T11:43:08.256339"
}
Docker
Next step is to dockerize the application but before that, I changed the use of a local SQLite database to using Postgres in production.
# Multi-stage build for Paper Supply Agent API
# Stage 1: Builder
FROM python:3.11-slim as builder
WORKDIR /build
# Install build dependencies
RUN apt-get update && apt-get install -y \
build-essential \
postgresql-client \
&& rm -rf /var/lib/apt/lists/*
# Copy requirements
COPY requirements-prod.txt .
# Create virtual environment and install dependencies
RUN python -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
RUN pip install --no-cache-dir -r requirements-prod.txt
# Stage 2: Runtime
FROM python:3.11-slim
WORKDIR /app
# Install runtime dependencies only
RUN apt-get update && apt-get install -y \
postgresql-client \
&& rm -rf /var/lib/apt/lists/*
# Copy virtual environment from builder
COPY --from=builder /opt/venv /opt/venv
# Set environment variables
ENV PATH="/opt/venv/bin:$PATH" \
PYTHONUNBUFFERED=1 \
PORT=8000
# Copy application code
COPY . .
# Create non-root user for security
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
# Health check
HEALTHCHECK --interval=30s --timeout=10s --start-period=40s --retries=3 \
CMD python -c "import requests; requests.get('http://localhost:8000/health', timeout=5)" || exit 1
# Expose port
EXPOSE 8000
# Run application
CMD ["uvicorn", "api:app", "--host", "0.0.0.0", "--port", "8000"]Deployment Scripts
Third step is build deployment / destruction scripts for the required AWS services to be able to run them automatically from a Github action following this architecture:
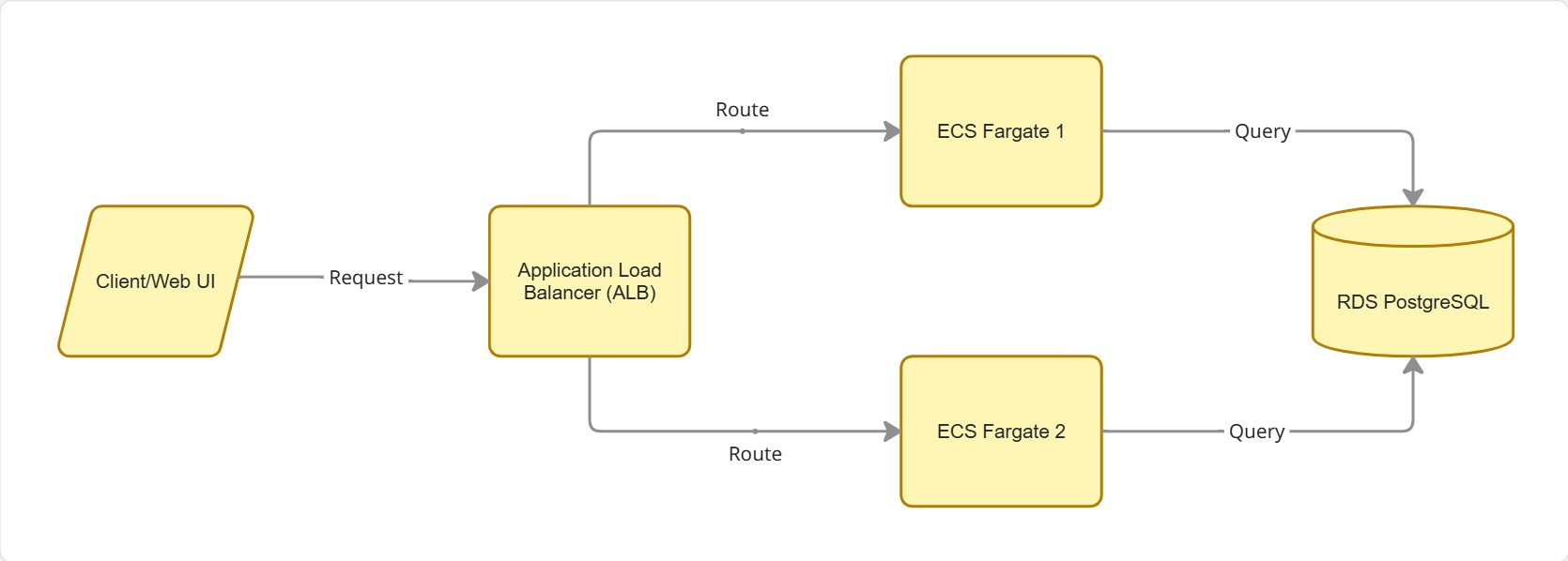
We can run one service and when there is an increase in requests, we can add another container and route requests between the deployed containers. This was successfully deployed to AWS.
Github Actions
Final step is create a deploy / destroy workflows in Github Actions which can work manually or through pushing to the P05 folder. You can view the code here.
name: P05 Deploy
on:
push:
branches:
- master
paths:
- "P05/**"
- ".github/workflows/p05-deploy.yml"
workflow_dispatch:
concurrency:
group: p05-deploy
cancel-in-progress: false
jobs:
deploy:
runs-on: ubuntu-latest
permissions:
contents: read
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Verify required secrets are set
run: |
set -euo pipefail
test -n "${{ secrets.AWS_ACCOUNT_ID }}"
test -n "${{ secrets.OPENAI_API_KEY }}"
test -n "${{ secrets.DB_PASSWORD }}"
- name: Make deploy script executable
run: chmod +x deploy_aws_resources.sh
working-directory: P05
- name: Deploy app and infrastructure
env:
AWS_REGION: ${{ secrets.AWS_REGION }}
AWS_ACCOUNT_ID: ${{ secrets.AWS_ACCOUNT_ID }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
DB_USERNAME: ${{ secrets.DB_USERNAME }}
DB_PASSWORD: ${{ secrets.DB_PASSWORD }}
PROJECT_NAME: ${{ secrets.PROJECT_NAME }}
run: ./deploy_aws_resources.sh
working-directory: P05And with that all learning objectives are now complete.
What do you plan to do this week?
I will extend the knowledge that I gained over the previous weeks to work on my capstone project for the remaining 4 weeks. I’ll probably be using LangChain, LangGraph and LangSmith to explore another multi-agentic building framework similar to the Hugging Face smolagents framework.
Are there any impediments in your way?
No, just some added pressure to finalize the final project for CSPB 3010 in addition to the capstone project here.
Reflection on the process you used last week — how can you make the process work better?
I’m really happy with the progress so far and how comfortable I was working with Github Copilot and making suggestions to update the codebase after setting the plan and reviewing the generated files.
Week 08 [Mar 9 - Mar 16, 2026]
What did you do last week?
Last week was quite busy, I managed to complete and submit the last project for the Udacity Agentic AI course and graduate. It did take sometime to complete but I’m happy to get exposed to what makes Agentic systems work.

The final project of the course is for the Beaver Choice Paper Company. The challenge is that the company is struggling with managing their paper supplies, responding promptly to customer inquiries, and generating competitive quotes. They’re overwhelmed and losing potential sales due to inefficiencies. We have to design and implement a multi-agent solution, restricted to at most five agents, capable of handling inquiries, checking inventory status, providing accurate quotations, and completing transactions seamlessly. The solution must ensure responsiveness, accuracy, and reliability in managing requests and maintaining optimal stock levels.
System Overview
The system uses 5 agents built on the smolagents (ToolCallingAgent) framework to automate paper supply order processing. An LLM-based ParsingAgent handles natural language understanding, while business logic agents remain deterministic.
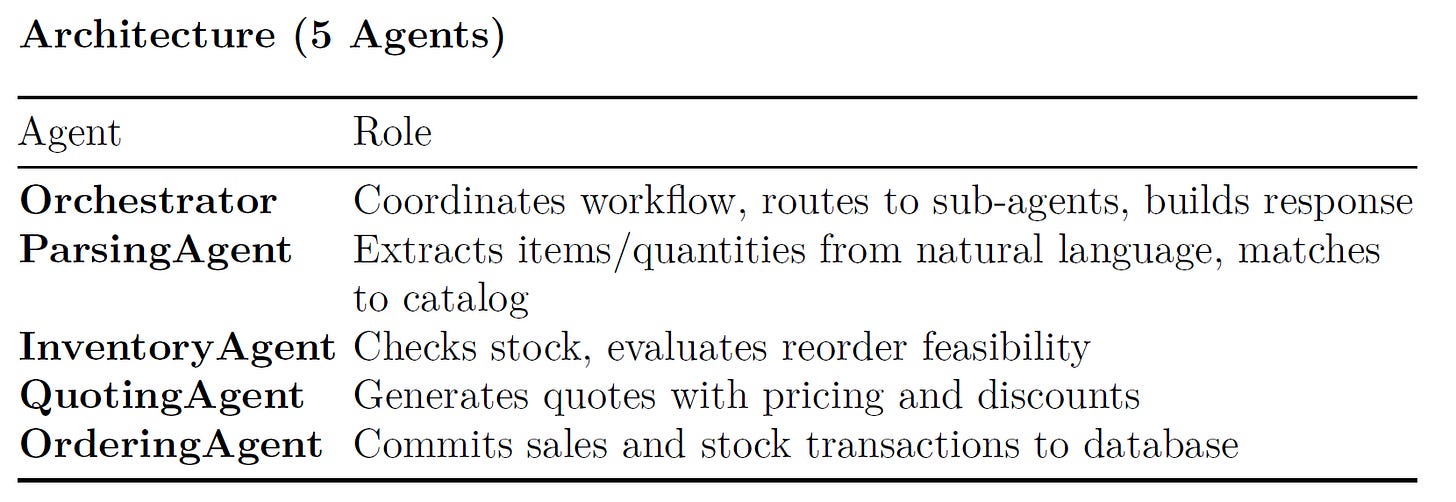
Workflow Explanation & Design Rationale
The architecture separates concerns into five single-responsibility agents, each owning one stage of the order pipeline:
1. Orchestrator
Acts as the central coordinator. It receives the raw customer request, delegates to each downstream agent in sequence, and assembles the final response. By keeping orchestration logic in a dedicated agent, the workflow is easy to modify (e.g., adding a new validation step) without touching individual agent implementations.2. ParsingAgent
The only agent that relies on an LLM. Customer requests arrive as free-form natural language with varied phrasing (“500 sheets of glossy”, “10K A4”, “printer paper”). Rather than maintaining brittle regex patterns or synonym dictionaries, the system delegates parsing to an LLM that receives the full product catalog and returns structured item/quantity pairs. This design choice trades determinism for flexibility: the agent handles synonyms, abbreviations, and novel phrasing withoutcode changes.
3. InventoryAgent
Performs deterministic stock and feasibility checks. For each parsed item, it queries the database to verify stock levels, checks whether the company’s cash balance supports a restock order, and compares supplier ETAs against the customer’s delivery deadline. Separating inventory logic lets it be tested and reasoned about independently.
4. QuotingAgent
Computes pricing using catalog unit prices and applies volume-based discounts. It also reviews historical quote data for consistency. Isolating quoting from ordering ensures that a quote can be generated and inspected before any money changes hands.
5. OrderingAgent
The only agent with database write access. It commits sale transactions and, if needed, stock replenishment orders. By restricting writes to a single agent, the system minimizes the risk of inconsistent state from partial failures.
This sequential pipeline was chosen over a parallel or fully autonomous multiagent design because each step depends on the output of the previous one (you cannot quote items that haven’t been parsed, or finalize an order that hasn’t been assessed). The strict ordering also makes the system easier to debug failures can be traced to the exact stage that produced unexpected output.Evaluation (Evals)
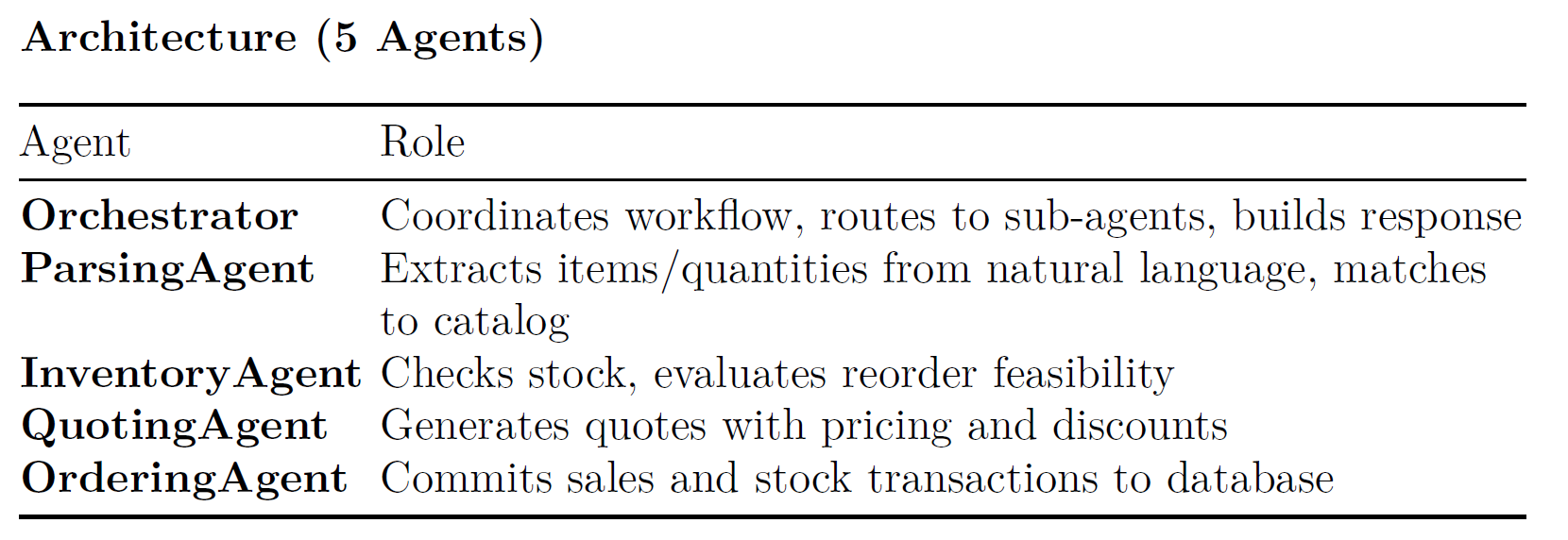
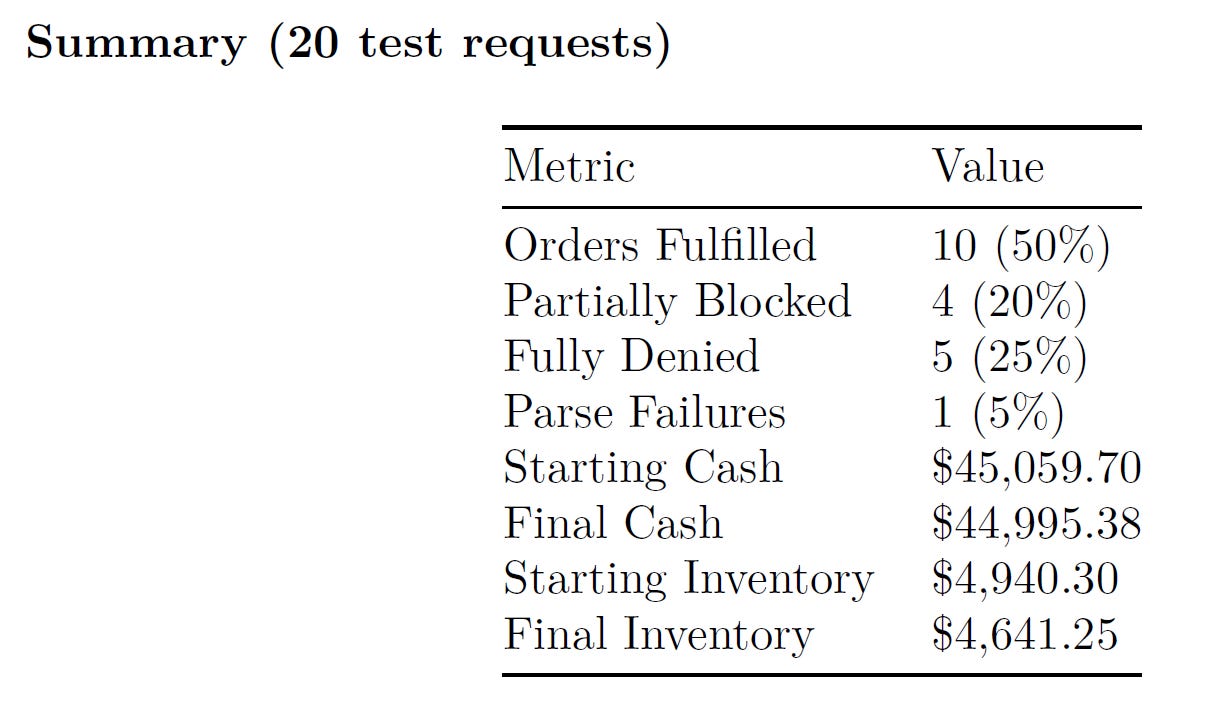
Here is the final workflow diagram for the multi-agent system
If you’re interested to review the code, then check this link.
In addition, I managed to review the additional learning resource requirement for the Github Actions certification from Linkedin and Microsoft Learn and successfully sat the exam.

What do you plan to do this week?
This week and upon the recommendation of Prof. Guinn, will deploy an AI agent to production. I have a rough plan of how to do that and will use the project I worked on in the Udacity course for deployment.
The plans is as follows:
Open up an endpoint for my agentic system to receive customer requests. That can be done by using FastAPI.
Dockerize the application and push the image to ECR (Amazon Elastic Container Registry)
Create a running container from the stored image in ECS (Amazon Elastic Container Service)
Build a Github Actions workflow to allow automated CI/CD
Are there any impediments in your way?
I got ahead of my initial plan to allow for more time to work on deployment and my personal project. In other words, a complete 4 weeks to complete my personal project.
Reflection on the process you used last week — how can you make the process work better?
With suggestions from Prof. Guinn and putting in more work this week, I believe that I can comfortably achieve my goals during the remaining 5 weeks.
Week 07 [Mar 2 - Mar 9, 2026]
What did you do last week?
Started Course #4 of the program. It is all about applying all the bits and pieces we learned in previous weeks into multi-agentic systems.
First concept is about multi-agent architecture design and answering the following questions to carefully design multiple agents that can effectively work with each other:
Who does what? (What does each agent specialize in?)
How do they talk to each other? (directly or through a manager/orchestrator or not at all)
What are the rules of engagement? (solving for conflict and recovering from failures).
How do we save and manage the state of agents? and how does data flow from agent to agent?
Second concept is the introduction of Smolagents as a multi-agentic framework.
It is a Python framework for building multi-agent systems powered by large language models (LLMs). It is designed to make it easy to create, orchestrate, and manage agents that can use tools (Python functions), maintain state, and collaborate to solve complex tasks.
Smolagents lets us build intelligent, tool-using, multi-agent systems with LLMs and Python, making it easy to combine language understanding with real-world actions and stateful workflows.
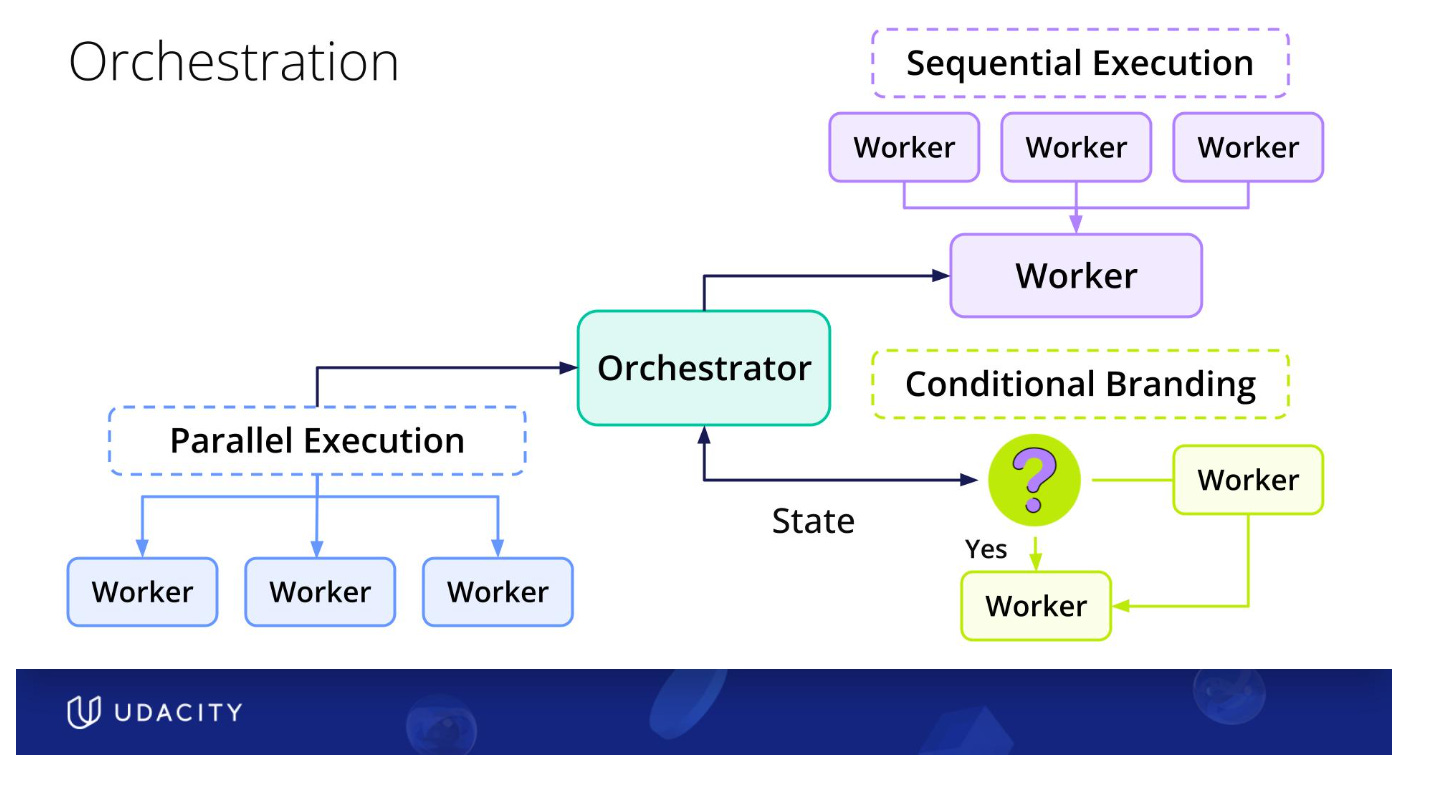
Third concept is about organizing agents around an orchestrator that acts as a Project Manager that:
Delegates tasks to specialized agents providing them with the necessary information to do their job.
Handles response from the specialized agents.
Manages state (keeping track of program and retaining information)
Recovers from errors and failures.
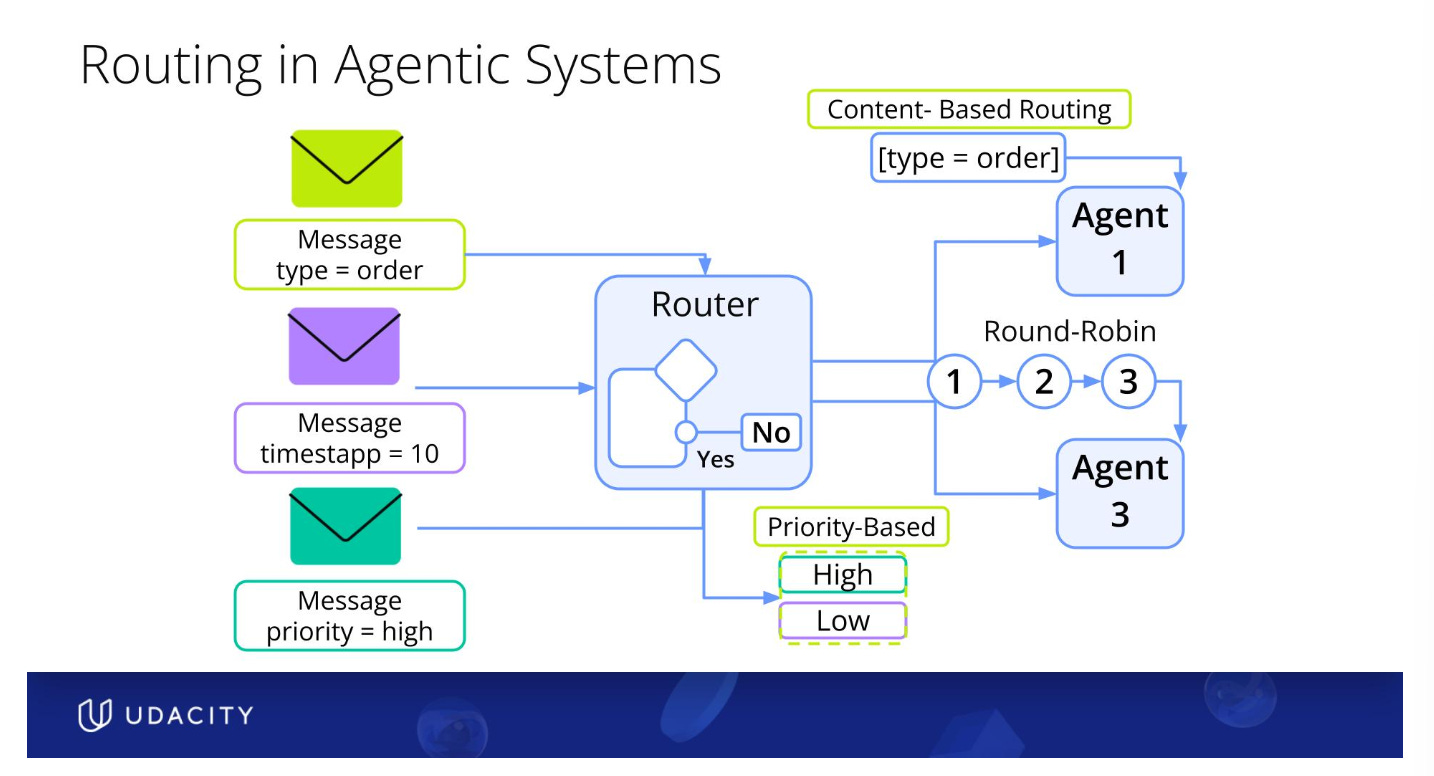
Fourth concept is handling routing between agents and how can that happen using:
Content based Routing: by looking at keywords or data types.
Round Robin Routing: Divide tasks equally usually among the same kind of specialized agents
Priority Based Routing: Check the priority of tasks and accelerate the execution of high priority tasks.
In addition, we need to manage the data flow between agents especially if we are mixing structured and unstructured data together so that each agent can receive information in a format that it understands.
What do you plan to do this week?
This week, I intend to complete the fourth course with exploring the following three concepts:
State Management in Multi-agentic systems and understanding the difference between conversation level state (short term memory) and system level state (long term memory)
How do we coordinate state between different agents and the importance of the orchestrator to do that?
How to use RAG to empower multiple agents to work together to solve complex tasks.
Are there any impediments in your way?
There shouldn’t be any problems or anticipated delays this week.
Reflection on the process you used last week — how can you make the process work better?
I put additional effort last week to keep on track and am planning to hopefully allocate some more time during Spring break to finish the course in order to spend more time on the capstone project.
Week 06 [Feb 23 - Mar 2, 2026]
Mid Project Update
My progress so far is going nearly as planned with a couple of days of delay so far which I anticipate being able to cover during Spring Break at the latest.

1. Learning Objectives

2. Completed Weekly Tasks
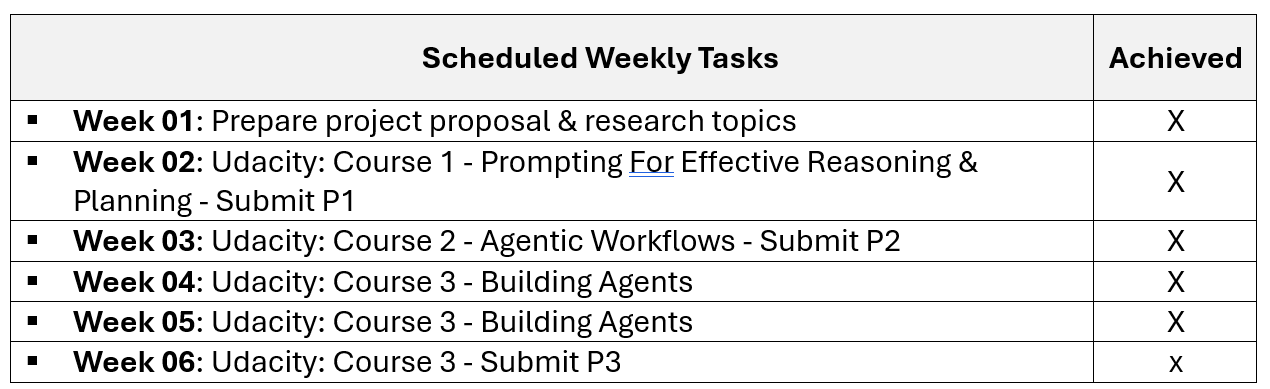

3. Remaining Weekly Tasks
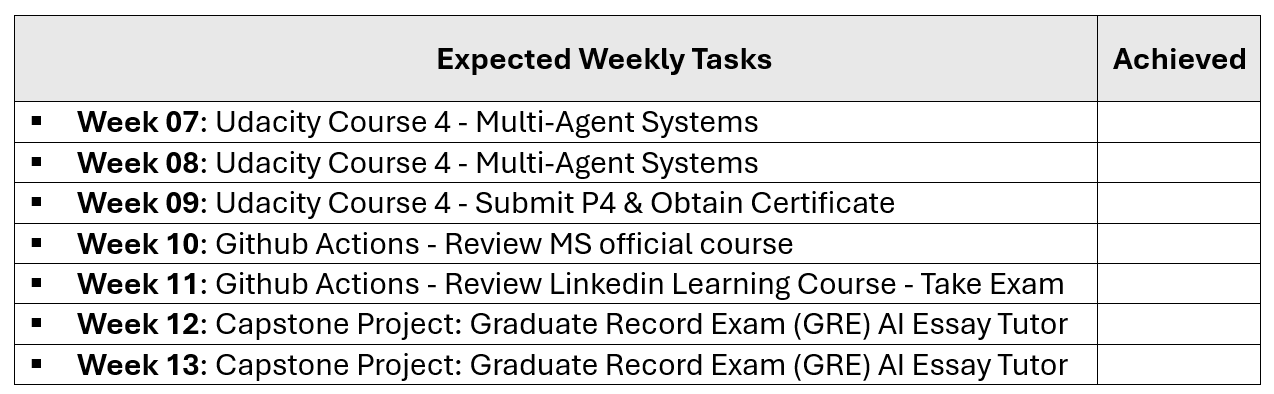
4. Reflection
This project has been a good steppingstone into the world of Agentic AI. Although the progress of the field is phenomenal (with moltbots now on the loose); I believe I have understood the building blocks of AI Agents and am excited to apply all my learnings to the specified capstone project. Taking this course with the Intensive Programming Workshop is turning out to be a bit of a chore which is sometimes affecting my progress overall.
Week 05 [Feb 15 - Feb 23, 2026]
What did you do last week?
Completed course #3 as part of the Udacity Agentic AI course. The concepts are really interesting which involved:
Function calling with tools which involves having the LLM trained to recognize function call requests in its prompt.
Structuring output using Pydantic so that it can be easily validated.
Modelling agentic workflows as state machines where each step execution has inputs that are processed to produce outputs (e.g. LLM processing, tool calling, termination, etc…)
Short Term memory can be modelled as a collection of workflows that are available and fed back to the LLM during one session (each session would have multiple prompts/interactions)
Sometimes the Agent needs to query updated (past its training data cutoff date) and unstructured data so it can use an API to execute searches on the web and return a structured output.
Agents need to query data from databases such as SQL, NoSQL or vector databases. For SQL databases, the agent would have to convert text to SQL.
Retrieval Augmented Generation (RAG) is an important framework to search relevant knowledges for specific and particular information. This is done by querying a knowledgebase first which doesn’t necessarily need to be a vector database like Pinecone or Chroma.
Long Term memory is needed to personalize agents across sessions and there are three types:
Semantic Memory: Facts and Knowledge
Storing important facts like the user’s name for example that can be retrieved using similarity searches.Episodic Memory: Events and Experiences
Provides few shot examples and summaries of previous interactions for how the agent dealt with similar cases before.
Procedural Memory: Behavior and Patterns
This allows the agents to adapt its rules and prompts to specific requests such as maintaining a certain tone of voice. So with each interaction, the agent adapts to its users.
Finally, evaluating the Agent’s output for
Task Completion
Quality Control
Tool Interaction
System Metrics
We can evaluate agents using:
Final Response Evaluation: After a task, look at the final output.
Single-Step Evaluation: Evaluate a single decision.
Trajectory Evaluation: Trace the entire path the agent took.
So to build effective evaluation, we would need inputs, outputs, reference data and evaluators (such as LLM Judge for example)
What do you plan to do this week?
I intend on working on the third project which involves developing an assistant called UdaPlay. Executives, analysts, and gamers want to ask natural language questions like:
Who developed FIFA 21?
When was God of War Ragnarok released?
What platform was Pokémon Red launched on?
What is Rockstar Games working on right now?
The agent should:
Attempt to answer the question from internal knowledge (about a pre-loaded list of companies and games)
If the information is not found or confidence is low, search the web
Parse and persist the information in long-term memory
Generate a clean, structured answer/report
Are there any impediments in your way?
There shouldn’t be any problems or anticipated delays this week.
Reflection on the process you used last week — how can you make the process work better?
I was expecting a more detailed explanation and implementation of Anthropic’s Model Context Protocol (MCP) as a standard way to use external tools and APIs but the course glossed over it quickly and so will be looking to supplement my knowledge with more information.
Week 04 [Feb 8 - Feb 15, 2026]
What did you do last week?
I started with course #3 as part of the Udacity Agentic AI course. This course goes deeper into using tools, formatting structured output, interacting with databases, using RAG and adding short and long term memory support. I’m about 60% done with the nanodegree.
I managed to review the first part about utilizing tools and will be continuing with the course content today. Managed to squeeze some work in between my traveling last week and working on the large first project for the Intensive Programming Workshop.
I also managed to watch Ben Snyder’s AI talk and especially enjoyed the intersection of sociology with computer science which involves a lot of graph and network theory.
What do you plan to do this week?
I intend on completing the course videos and coding exercises to allow some time to work on the course project next week.
Are there any impediments in your way?
There shouldn’t be any problems or anticipated delays this week.
Reflection on the process you used last week — how can you make the process work better?
I would say reviewing and marking the tough weeks and adding a bit of buffer in beforehand. And putting the work in even for 20 or 30 minutes during the week regardless of other commitments to push forward a little during the tough weeks.
Week 03 [Feb 1 - Feb 8, 2026]
Last Week:
I worked on the second project in the Udacity Agentic AI course where I got into more detail about the different agentic patterns, including running agents in parallel or sequence, having an intelligent orchestrator to route prompts to the most relevant agent as well as study two agentic workflows:
The first being the evaluator-optimizer workflow where we using LLM judging to assess if the output of the LLM meets our passing criteria. if the evaluation fails, another iteration happens with feedback generated from the first failure fed back as a prompt to the workflow.
The second is the orchestrator-worker workflow where specialist agents handle very specific tasks and the orchestrator routes the tasks to their best agents before terminating with the final response. We should have tasks first and that’s where Chain of Thought is important to divide our prompt into actionable tasks.
This project is also really interesting and is based on setting up an agentic software project management workflow to help build a sprint backlog for development from a set of customer requirements.
Here’s an excerpt from the final result:
**Feature 1: Automated and Efficient Email Handling**
- **Task ID: T001**
- **Task: Develop Email Response Automation Module**
- **User Story Reference**: US001 - As a user, I want routine inquiries to be automatically handled so that I can focus on more complex tasks.
- **Detailed Description**: Build logic to identify routine inquiries by analyzing email content patterns. Develop algorithms to generate automated responses using natural language processing. Integrate a library of standardized responses into the system to ensure consistency.
- **Acceptance Criteria**: Routine inquiries are correctly identified and responded to with a 95% accuracy rate. Automated responses are generated within 2 seconds.
- **Estimated Effort**: 40 hours
- **Dependencies**: Completion of the standardized response library (T002).
- **Task ID: T002**
- **Task: Design and Implement Standardized Response Library**
- **User Story Reference**: US002 - As a user, I want a library of standardized responses to ensure consistent communication.
- **Detailed Description**: Create a database to store common inquiries and responses. Develop a system for easy access and retrieval of these responses, ensuring they are up-to-date and relevant.
- **Acceptance Criteria**: The library contains at least 100 standardized responses and can be accessed in under 1 second.
- **Estimated Effort**: 30 hours
- **Dependencies**: None
- **Task ID: T003**
- **Task: Testing and Validation**
- **User Story Reference**: US003 - As a user, I want to ensure the accuracy of automated responses to maintain customer satisfaction.
- **Detailed Description**: Perform unit and integration testing to ensure response accuracy. Validate the consistency and accuracy of the automated responses through user testing and feedback.
- **Acceptance Criteria**: Automated responses pass all test cases with a 95% success rate.
- **Estimated Effort**: 20 hours
- **Dependencies**: Completion of T001 and T002.This is pretty amazing and I’m only using GPT-4o as the LLM processor.
So the project is in review and will keep you updated with the outcome.

You can check the source code for the second project here.
This Week:
I will start studying course #3 which is building agents with access to memory (short/long term), databases and tools.
Impediments:
I travelled to attend a startup conference in Dubai and although I finished the work a bit early, I couldn’t submit and provide my progress till today. I’m taking the intensive programming workshop too and we have a deadline for the first project next week which may slow down my progress a bit for professional development till I’m able to submit the project.
Reflections / Improved Process:
I’m still not sticking to a strict schedule but am doing fine up till now with my schedule being a bit fluid around priorities, work, life and other course requirements. I’ll be monitoring this closely to make sure I don’t slip on the way to the finish line.
Week 02 [Jan 26 - Feb 1, 2026]
What did you do last week?
I successfully completed Course #1 and passed the first project.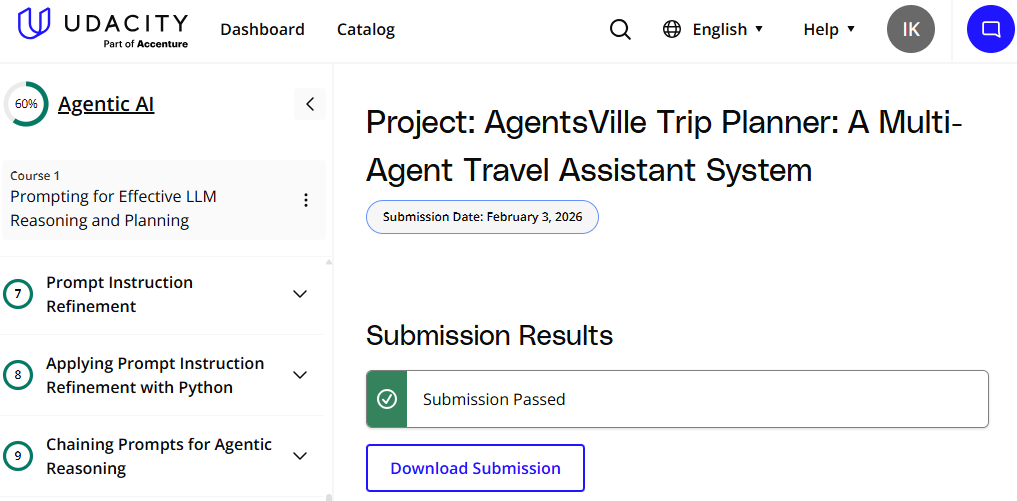
One thing I really like about Udacity is that their projects are reviewed by humans to provide detailed feedback and code reviews (don’t know if they’re still using humans or have shifted to AI grading after the Accenture acquisition).

I added the review above to summarize my takeaways from the lesson. Agentic AI is all about system design and less about actual machine learning. LLMs are treated as black boxes with prompts as inputs to the system and assistant responses as outputs. This distinction will become important in Course #2 as I work on workflow design.


First step to optimize the system is to work on refining the input. In other words, how do we construct a good prompt?
The course suggests to divide the prompt into 5 sections as follows:
[Role]: The persona the LLM should adopt (e.g., “Act as a high school teacher.”).
[Task]: The specific instruction or question (e.g., “find a solution to the following trigonometric identity.”).
[Output Format]: How the response should be structured (e.g., “One sentence answer”).
[Examples]: Sample input/output pairs
(e.g., “Q: What is the value of
\(sin^2(x) + cos^2(x)\)A: It is 1”).
[Context]: Additional information needed for the task (e.g., current date, if asking for the date).
Use Chain of Thought (CoT), which is a process to divide tasks into smaller sized sub tasks executing one after the other. This is accomplished by explicitly mentioning in the prompt to “Reason step by step”.
ChatGPT explains this quite well:
CoT is the agent’s internal deliberation / scratchpad that helps it:break a goal into steps (“what sub-problems do I need to solve?”)
choose the next action (“which tool/API should I call?”)
keep state (“what have I learned so far?”)
handle errors (“that tool failed—what’s the fallback?”)
Insure that we specify a schema for the output and validate the output. This can be done by using Pydantic models and asserting if the LLM output adheres to the specified schema. Here is an example from the Pydantic documentation:

and an output field can be verified by asserting the following:
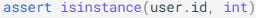
the
model_validate()class function can be used as well to validate the LLM output against the schema.Use ReAct (Reasoning /Acting framework)

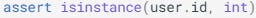
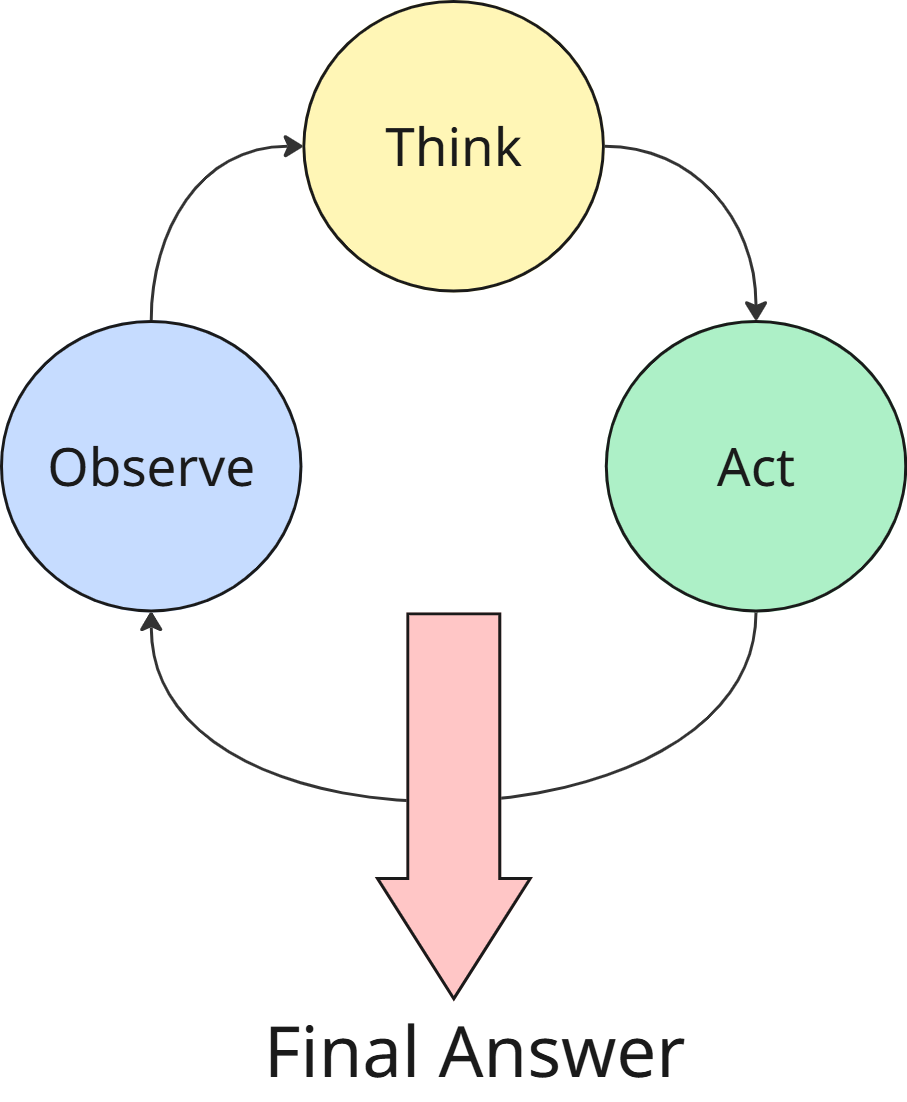
ReAct is a pattern where the LLM can alternate between thinking and taking actions:
Think: a step where an LLM can decide what’s missing and what to do next (e.g. “I need to get the current date to find suitable events”)
Act: perform an action or call a tool (e.g. “use tool get_current_date with no arguments“ )
Observe: Read the result and use it to choose the next step (e.g. “Today is February 4, 2026, now I can filter events for today.”)
Final Answer: This loop repeats until the model has enough information, then it produces a Final Answer.
The purpose is to reduce hallucinations by checking real world information.
I applied these concepts to a travel AI agent that plans a trip to the wonderful city of AgentsVille! You can check the code here.
What do you plan to do this week?
This week, I’ll be continuing with Course 2 from the Udacity Nanodegree looking at Agentic workflow patterns such as prompt chaining, parallelization and routing and then I’ll review two important agentic workflows:Evaluator-Optimizer workflow
Orchestrator-Worker workflow
Are there any impediments in your way?
Currently no problems in sight.Reflection on the process you used last week, how can you make the process work better?
To be truthful, I didn’t stick to my slotted time and had to delay it from my scheduled Friday sessions to the next available times on Monday and Tuesday when I reviewed the course content and completed the project on one day and then worked on my blog post and providing updates on the second. I still have my next scheduled session on Friday and I hope that I can stick to it this time. I feel that spacing out my work between sessions helps me process and recall concepts better.
Week 01 [Jan 20 - Jan 26, 2026]
I’ll be providing Agile style weekly standup updates and here’s the first one:
What did you do last week?
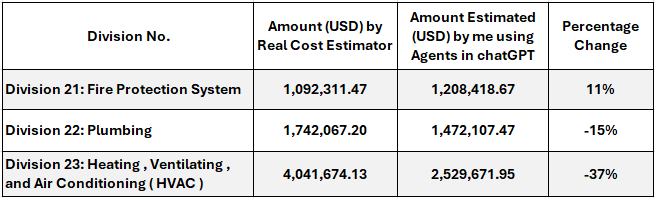
Last week was focused on narrowing my topic of interest and since I’m on a trajectory to develop my AI skills, I went for Agentic AI. It’s a trendy topic and I’d love to gain a better understanding.I’ve been experimenting with construction cost estimations on several projects using line item descriptions and a basic knowledgebase of two previously priced construction projects with chatGPT in Thinking mode (i.e. using agents) but with mixed results. Here’s a sample of a project that was recently estimated using AI agents vs a real cost estimator for mechanical works in a 5 stars hotel:
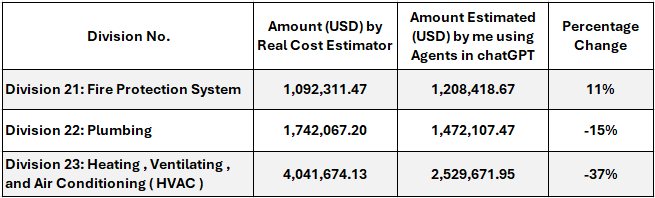
I’m working on refining the AI system architecture for better use of short and long term memory as well as vector databases for Retrieval Augmented Generation (RAG). Therefore, I’ve identified the Udacity Agentic AI course as the source for my learning throughout the next 13 weeks.
What do you plan to do this week?
I’ve already started with the first module of the Udacity Agentic AI course and will be completing and submitting the first project this week. I’ll then be writing my first article summarizing my learnings from the week.Are there any impediments in your way?
Currently no problems in sight.Reflection on the process you used last week, how can you make the process work better?
I haven’t really tested the process last week but with the plan set in the proposal, I’ll be starting to time my commitment to the slotted weekly study time.